
In slechts 3 seconden kan een AI die je nog nooit heeft horen praten, je stem perfect imiteren. Dit is de nieuwste prestatie van de kunstmatige intelligentie van Microsoft - het VALL-E tekst-naar-spraakmodel, dat de stem van iedereen naar believen kan kopiëren met slechts 3 seconden spraak.
Microsoft VALL-E imiteert onze stem na slechts 3 seconden spreken
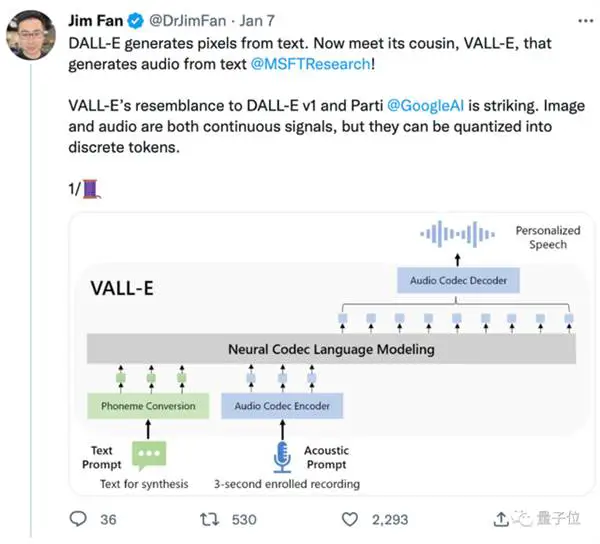
Het is ontstaan uit DALL E, maar is gespecialiseerd in audio, en het tekst-naar-spraak-effect werd populair nadat het online was uitgebracht.
Sommige gebruikers zeiden dat als VALL·E en ChatGPT worden gecombineerd, het resultaat verbluffend zal zijn. Voor anderen lijkt de dag dat het mogelijk wordt om met AI te videobellen niet ver weg. Er zijn er zelfs die grappen dat nadat de AI voor de schrijvers en schilders heeft gezorgd, de stemacteurs aan de beurt zijn.

Maar hoe imiteert VALL·E een “ongehoord” geluid in 3 seconden?
VALL-E analyseert audio met taalmodellen. Het synthetiseert spraak op basis van AI "ongehoorde" geluiden, d.w.z. zero-sample learning.
De traditionele tekst-naar-spraak-oplossing is in feite een pre-workout-modus samen met een fijnafstelling. Als het wordt gebruikt in een nulmonsterscenario, resulteert dit in een slechte gelijkenis en natuurlijkheid van de gegenereerde spraak.

Op basis hiervan kwam VALL-E uit het niets en stelde een ander idee voor dan het traditionele vocale model.
Vergeleken met het traditionele model dat het Mel-spectrum gebruikt om kenmerken te extraheren, beschouwt VALL-E spraaksynthese direct als een taak van het taalmodel, het eerste is continu en het laatste is discreet.
Met name het traditionele spraaksyntheseproces is vaak het pad van "foneem → mel-spectrogram (mel-spectrogram) → golfvorm".
Maar VALL -E transformeerde dit proces in "foneem → discrete audiocodering → golfvorm":
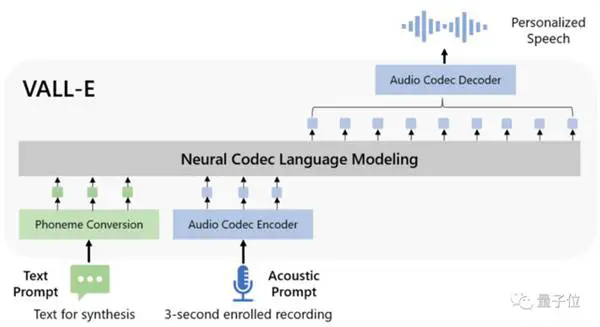
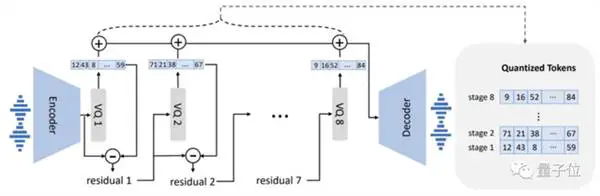
Qua modelontwerp is VALL-E ook vergelijkbaar met VQVAE. Kwantiseert audio in een reeks discrete tokens. De eerste kwantiseerder is verantwoordelijk voor het vastleggen van de audio-inhoud en identiteitskenmerken van de spreker, terwijl de tweede kwantiseerder verantwoordelijk is voor signaalverfijning. wat natuurlijker klinkt:
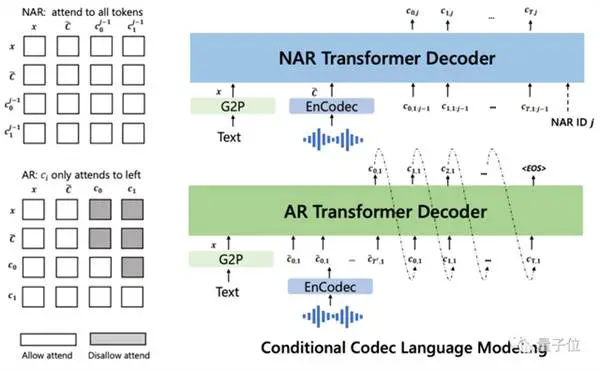
Vervolgens geconditioneerd door de tekst en de audioprompt van 3 seconden, voert het autoregressief een discrete audiocodering uit:
Maar niet alleen dat, naast zero-sample spraaksynthese ondersteunt VALL-E ook spraakbewerking en het maken van spraakinhoud in combinatie met GPT-3.
Het omgevingsgeluid op de achtergrond kan ook worden hersteld
Te oordelen naar de gesynthetiseerde vocale effecten, kan VALL-E meer herstellen dan alleen het timbre van de spreker.
Niet alleen wordt de toonhoogte ter plekke nagebootst, maar het ondersteunt ook verschillende spraaksnelheden. Dit zijn bijvoorbeeld twee verschillende spraaksnelheden die door VALL-E worden geleverd wanneer dezelfde zin twee keer wordt uitgesproken, maar de toonovereenkomst nog steeds hoog is:
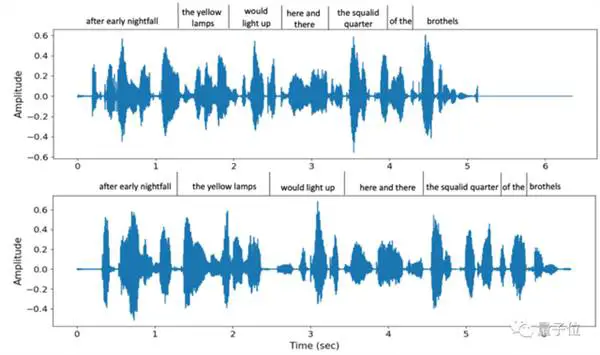
Tegelijkertijd kan ook het omgevingsgeluid op de achtergrond van de andere partij nauwkeurig worden hersteld.
Bovendien kan VALL-E een verscheidenheid aan emoties van de spreker nabootsen, waaronder verschillende soorten zoals boos, slaperig, neutraal, vreugde en misselijkheid.
Het is vermeldenswaard dat de dataset die wordt gebruikt voor de VALL·E-training niet bijzonder groot is.
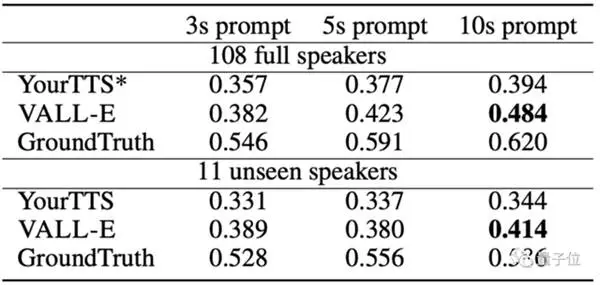
Vergeleken met OpenAI's Whisper, waarvoor 680.000 audiotrainingsuren nodig waren en slechts meer dan 7.000 sprekers en 60.000 trainingsuren werden gebruikt, overtrof VALL-E vooraf getrainde tekst-naar-spraak in termen van gelijkenis met Model YourTTS tekst-naar-spraak.
Verder hoorde YourTTS tijdens de training vooraf de stemmen van 97 van de 108 sprekers, maar komt het in de daadwerkelijke test nog steeds tekort voor VALL-E.
Wat betreft de velden waarin het kan worden toegepast:
Het kan niet alleen worden gebruikt om uw eigen stem na te bootsen, zoals mensen met een handicap helpen een gesprek met anderen te voeren, maar u kunt het ook gebruiken om voor u te spreken wanneer u dat niet wilt. Natuurlijk kan het ook worden gebruikt voor het opnemen van audioboeken.
VALL-E is echter nog geen open source en het kan zijn dat u nog even moet wachten om het uit te proberen.
In de aanbieding op Amazon







